Structural Equation Modeling - SEM
Kali ini kita mencoba explore terkait SEM dengan Stata.
Pembahasan akan dijadikan beberapa bagian.
Referensi tulisan ini:
o http://fmwww.bc.edu/EC-C/S2017/8823/ECON8823.S2016.nn15.slides.pdf
o http://www.stata-press.com/data/r13/sem_sm2.dta
o Buku "Praktikum Analisis Statistik dengan Stata 12", Surya Darma, 2020
Structured Equation Modeling
SEM menggabungkan beberapa model pengukuran yang sebelumnya telah ada yaitu: (i) membahas hubungan antara variable yang bisa diukur (measured varible) dengan variable yang tidak bisa diukur (latent variable) menggunakan path analysis, dan menghubungkan variable-variable tsb dengan faktor penyebabnya (causal factor).
Contoh:
Pada kasus binomial probit model (model regresi dimana dependent variable nya hanya 1 atau 0), yaitu: Keputusan Membeli.
Keputusan Membeli ini disebabkan orang akan berpikir apa net benefit yang dia dapat. Sebagai contoh, membeli seharga Rp. 1 juta, mendapatkan jumlah barang terentu. Ada variable yang bisa diukur disini yaitu harga barang, jumlah barang, tingkat kepuasan pelayanan, dll. Sehingga keputusan (misalkan): "membeli".
Nah, variable "Keputusan Membeli" ini merupakan variable laten (tersembunyi), yang tidak diukur secara langsung, tapi bisa diukur dari faktor-faktor pembentuknya.
Contoh Kasus:
Contoh kasus berikut merupakan contoh SEM klasik, dari Buku "SEM with Stata", Acock, 2013, yaitu tentang analisa konsep Keterasingan (alienation) Individu.
Terdapat 3 variable latent: alineation tahun 1967 (alien67), alienation tahun 1971 (alien71), dan social economic status (status sosial) tahun 1966.

Diasumsikan variabelsocial status tahun 1966 mempengaruhi alienasi tahun 1967 dan juga mempengaruhi alienasi tahun 1971. Variable SES66 ini dipengaruhi level pendidikan (educ66) dan juga status pekerjaan (occstat66). Sedangkan variable keterasingan dipengaruhi anomia (semacam penyakit syaraf yang menyebabkan seseorang sulit mengeri makna perkataan lawan bicara), dan powerlessness (ketidakberdayaan).
Dalam model diatas ada 3 laten variable:
SES66 (exogenous)
Alien67 (endogenous)
Alien71 (endogenous)
Jika kita jalankan di SEM Builder Menu berikut:
Estimation --> Estimate --> Model: Maximum Likehood | Reporting: Display Standardized Coeficient and Values
maka akan didapat hasil sbb:

Terlihat bahwa: SES66 berpengaruh negatif ke Alien67 dan Alien71 sebesar -0.57, dan -0.15. Artinya semakin tinggi social economic status seseorang, semakin turun tingkat alineasinya. Demikian juga ada kontribusl Alien67 kepada Alien71 sebesar 0.66.
Sekarang kita periksa Goodness of Fit dari model tsb, untuk memeriksa seberapa variance dari masing-masing endogenous variable mampu dijelaskan oleh model.
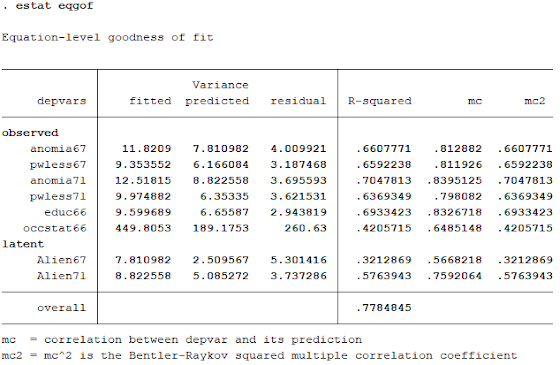
Kita lihat bahwa model mampu menjelaskan Alien67 sebesar 32.13% (R-Squrared). Dan model mampu menjelaskan Alien71 sebesar 57.74%.
Idealnya berdasarkan Buku Pak Surya (lihat halaman 114) dengan jumlah sampel hanya 15, maka loading factor dikatakan fit, jika nilainya > 0.75.
Terlihat loading factor yang tidak memenuhi kriteria tsb:
SES66 --> occstat66: 0.65
dan juga antara laten variable.

Goodnees of fit
p>chi2: 0.00 > 0.05 (false: artinya Ho ditolak, berarti model tidak begitu fit)
RMSEA: 0.108 <= 0.08 (false: artinya model tidak begitu fit)
CFI: 0.969 > 0.9 (true: artinya model fit)
SRMR: 0.021 < 0.08 (true: artinya model fit)
Terlihat bahwa model berdasarkan chi2 probability seharusnya H0 (model fit) ditolak, tapi dalam aturan SEM tidak otomatis di tolak.
Dapat disimpulkan bahwa model belum begitu fit.
Bagaimana cara mengimprove model?
Salah satu caranya adalah dengan membuat model lebih kompleks (dengan cara menambahkan degree of freedom). Kita tahu bahwa antara error dimodelkan tidak ada correlasi. Kita bisa coba mengkorelasikan error:
e.anomia67 --correlate-- e.anomia71
e.pwless67 --correlate-- e.pwless71
Indikasis ini bisa didapatkan juga dengan menjalankan
.estat mindices

Setelah ditambahkan korelasi antara error variable tsb, gambarnya dan hasil mejalankan: di SEM Builder Menu berikut:
Estimation --> Estimate --> Model: Maximum Likehood | Reporting: Display Standardized Coeficient and Values
maka akan didapat hasilnya:

Terliha loading factor SES66 -- Alien71 meningkat dari -0.15 menjadi -0.21, dan efek dari Alien67 ke Alien72 telah berkurang dari 0.66 ke 0.57.
Covariance antara e.anomia juga positif, demikian juga dengan covariance e.pwless juga positif yang tidak 0.

Likehood Ratio (LR) test antara model vs saturad Prob nya 0.3111 artinya > 0.05, sehingga H0 diterima, artinya sekrang model sudah fit.
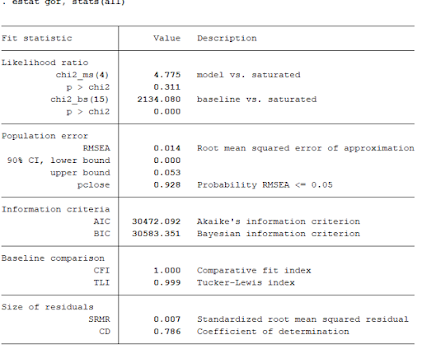

Terlihat bahwa model mampu mejelaskan R-squared variable Alien67 dan Alien71 sebanyak 31.7% dan 49.7% (terjadi penurunan sedikit dari sebelumnya).
Goodnees of fit
p>chi2: 0.311 > 0.05 (true: artinya Ho diterima, berarti model fit)
RMSEA: 0.014 <= 0.08 (true: artinya model fit)
CFI: 1.000 > 0.9 (true: artinya model fit)
SRMR: 0.007 < 0.08 (true: artinya model fit)
Terlihat bahwa sekarang model sudah fit.
Comments
Post a Comment