ROADMAP ILMU STATISTIK
Bagi pemula di dunia statistik, [seperti saya ini yang masih pemula menggunakan software statistik:) hehe], setelah membaca dan ngulik, saya menyimpulkan bahwa ilmu statistik adalah sebuah ilmu yang berisi perangkat-perangkat yang mana dengan perangkat-perangkat tsb seseorang bisa menginterpretasikan sampel data dan menginferensikan nya ke dalam populasi. [revisi ternyata ada beda antara statistika dan statistik lihat di sini di sini]
Untuk menginterpretasikan sample tersebut perlu alat buat mengujinya. Dan ini biasanya dibuat dengan mengajukan Hipotesis 0. Lawan dari Hipotesi 0 adalah Hipotesis 1 (atau disebut juga Hipotesis alternatif).
Dalam pengujian hipotesis tersebut, diperkenalkan konsep nilai alpha 0.05 (atau 5%), dan dihitung p value (probalility value nya).
Dengan kriteria sbb:
p < 0.05 maka H0 ditolak
Banyak metode yang digunakan untuk mengetes sample, tergantung type data yang dimiliki, dan berapa banyak variabel yang dibandingkan.
Dikenal metode-metode seperti: Chi Square test (Chi di baca "Kai"), t-test, Anova, dsb,
Berikut penjelasan ringkas metode-metode tersebut dengan Referensi https://www.youtube.com/watch?v=I10q6fjPxJ0
Awal cerita ROADMAP
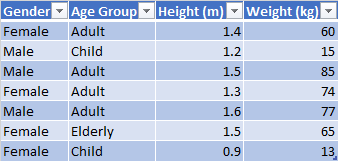
Di sebuah perumahan, diketahui ada sejumlah penduduk (disebut Populasi). Ingin diketahui berat (weight) dan tinggi (height) penduduk, disamping itu dilakukan pengkategorian (pengelompokan data) bedasarkan Gender (male, female), dan kelompok usia (child, adult, elderly).
Ada 2 pendekatan:
1. Semua penduduk di data. Ini namanya sensus. Biaya besar, tapi presisi (walau tidak 100%, karena masih mungkin ada kesalahan waktu interview, atau entry data).
2. Sebagian penduduk di data. Ini namanya sampling. Biaya murah, tapi tingkat ke presisian bisa diatur sedemikian sehingga bisa mendekati hasil sebenarnya.

Terlihat pada gambar diatas, dari Populasi, dipilih Sample, lalu di data. Ada 4 variable yang didata: Gender, Age Group, Height (m), Weight (kg).
Tugas Pertama Statistik
Tugas pertama Statistik adalah menganalisa, merangkum (summarize) dan menampilkan data secara deskriptif (visualisasi) sehingga pembaca data mendapatkan sesuatu arti yang meaningful.

Variable adalah sesuatu yang diukur di lapangan. Umumnya variabel bersifat Categorical atau Numerical. Biasanya Numerical ada unit nya (misalkan berat, tinggi). Mengenai Type Data akan dibahas pada bagian lain.
Perhatikan type data Numerical, standar summary yang bisa ditampilkan adalah: Range (min, max), Median, Mean, dan IQR (Inter Quartile Range).
Catatan dalam statistic: format penulisan, mean, median, dsb sbb:
| sample statistic | population parameter | description |
|---|---|---|
| n | N | number of members of sample or population |
| x̅ “x-bar” | μ “mu” or μx | mean |
| M or Med or x̃ “x-tilde” | (none) | median |
| s (TIs say Sx) | σ “sigma” or σx | standard deviation For variance, apply a squared symbol (s² or σ²). |
| r | ρ “rho” | coefficient of linear correlation |
| p̂ “p-hat” | p | proportion |
| z t χ² | (n/a) | calculated test statistic |
Contoh perhitungan Inter Quarter Range (IQR):

Oke, sekarang kita punya 4 variable:
Kita bisa melakukan analisa dengan banyak cara:
1. Hanya melihat kolom Gender saja, atau Age Group saja

Kolom kiri adalah summary, kanan adalah visualisasi.
Terlihat bahwa jika variable nya non numerik, maka kita bisa hitung frekuensinya.
2. Hanya melihat kolom Height saja atau Weight saja.

Terlihat bahwa jika variable nya numerik maka, data dapat disummary-kan menggunakan mean, median, stdev, dsb.
3. Kombinasi Categorical

Terlihat jika categorical, yang dihitung adalah frekuensinya.
4. Kombinasi numerical


5. Kombinasi Categorical dan Numerical

Terlihat bahwa kita bisa melakukan grouping dari variable Numerical berupa Range, IQR, Medium, Mean, berdasarkan Group dari Variable Categorical (Male, Female).
Tugas kedua Statistik, adalah menguji Hipotesis 0.
Sebelum pengujian itu diperlukan pernyataan dari Pertanyaan dan Hipotesis 0

Tools yang digunakan ada beberapa, tergantung kombinasi variable yang digunakan.

Terlihat bahwa ada banyak tools yang bisa digunakan, spt proportion test, chi squared test, t-test, ANOVA, correlation test.
Berikut elaborasinya dari teknik Test data statistiknya.
1. One Categorical
Pertanyaan: apakah jumlah populasi Female dan Male proporsi nya sama (50:50)
H0: Tidak ada perbedaan proporsi dari Male dan Female

Setelah dilakukan perhitungan dengan one sample proportion test didapat nilai p 0.03, dan ini dibawah nilai alpha 0.05, artinya H0 direject. Sehingga kesimpulannya: dalam populasi hipotesis bahwa proporsi jumlah Male dan Female sama tidak significant sehingga kesimpulan H0 ditolak, sehingga kesimpulannya adalah: dalam populasi terdapat perbedaan proporsi antara Male dan Female (H1).
2. Two Cetegorical Test
Pertanyaan: apakah jumlah populasi Female dan Male proporsi nya sama (50:50) dalam masing-masing Age Group? Atau bahasa lain: Apakah proporsi Male dan Female, tidak tergantung kepada Age Group?
H0: Proporsi Male dan Female tidak tergantung (Independent) terhadap Age Group

Setelah dilakukan perhitungan dengan chi-squared test, didapat p value didapatkan 0.03, lebih kecil dari nilai alpha, sehingga H0 ditolak.
Interpretasi: Hipotesis bahwa proporsi Male dan Female dalam populasi tidak tergantung dari Age Group (Child, Adult, Ederly) ditolak. Sehingga asumsi yang diterima adalah asumsi H1, yaitu bahwa proporsi Male dan Female dalam populasi bergantung kepada Age Group.
3. One Numerical Test
Selanjutnya jika di cek hanya variable Height, maka dengan apa bisa dibandingkan? Bisa dibandingkan dengan historical value.
Pertanyaan: apakah rata-rata tinggi tahun ini bebeda dari rata-rata tinggi dari tahun sebelumya?
H0: Tidak ada perbedaan rata-rata tinggi tahun ini dengan tahun sebelumnya

Setelah dilakukan t-test, didapat p value 0.03 lebih kecil dari alpha 0.05, sehingga asumsi H0 ditolak.

Setelah dilakukan t-test, didapat p value 0.03 lebih kecil dari alphe 0.05, sehingga H0 direject.

Setelah dilakukan correlation test, didapat p value 0.03 lebih kecil dari alpha 0.05, sehigga H0 ditolak.
Comments
Post a Comment